In the world of machine learning, the allure often lies in the dazzling advancements: the latest models, cutting-edge techniques, and breakthrough success stories. It’s comparable to admiring the tip of an iceberg without recognizing the substantial structure beneath the surface that keeps it afloat.
Machine learning projects require an immense amount of support work, encompassing data annotation, data validation, drift detection, model evaluation, and model version management, to name a few. While these foundational tasks are seldom highlighted in mainstream blogs and LinkedIn posts, they are essential for the success of any ML project.
The stark reality of production machine learning systems is that they demand far more than the visible, glamorous facets. The extensive labor supporting these systems might not grab headlines, but it’s unquestionably vital. This is why I liken ML projects to icebergs: the end-users rarely perceive or acknowledge the vast amount of work behind the scenes that goes into a successful ML project.
The advent of large language models (LLMs) has only expanded the iceberg. Why? Because with LLMs, we face more complex model evaluations, intricate fine-tuning processes, and the necessity for sophisticated infrastructure during deployments. It’s far from simply deploying a new foundational model in a notebook; it’s a comprehensive, multifaceted endeavor.
Feeling overwhelmed by the scope of work? One might consider leveraging closed-source model APIs like OpenAI, which handle many of these support tasks for you. However, there's a significant trade-off. If your competitive advantage relies on OpenAI prompts that are accessible to your competitors, your 'iceberg' might melt away rapidly, much like an ice cream cone on a hot day—unpredictably and messily.
Choosing to run open-source models presents its own set of challenges, but it comes with substantial rewards. It allows you to safeguard your intellectual property and, more crucially, protect your clients’ data. This approach offers a more sustainable competitive edge, ensuring your iceberg remains robust in the face of competition.
We invite you to follow our blog as we delve deeper into how we tackle our machine learning icebergs. By sharing our insights, strategies, and experiences, we aim to provide a comprehensive view of the less visible but critical aspects of ML projects. Join us in exploring the depths of machine learning and uncovering the full extent of what it takes to succeed in this dynamic field.
Deploying Large Language Models with Ease: Lessons Shared at AI in Production 2024
Digits attended the AI in Production 2024 Conference held in Asheville, North Carolina and shared our experience deploying Open Source Large Language Models (LLMs).
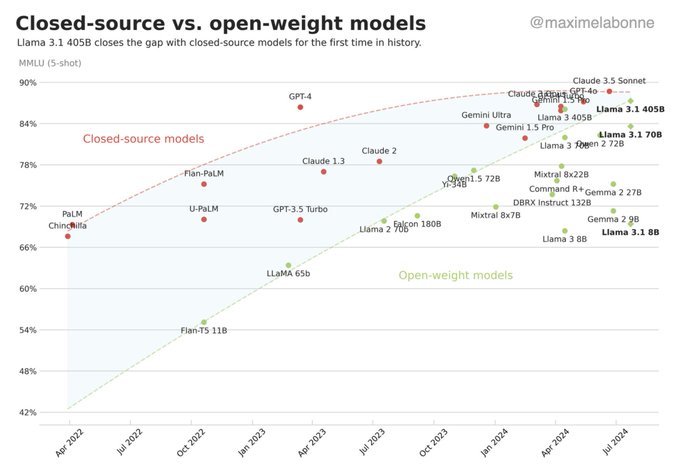
A few days ago, the CEO of Huggingface shared an astounding claim: open-source models are catching up fast to closed-source ones like OpenAI’s GPT-4. This is a major win for the open-source community and shows how AI is becoming more accessible to everyone. But, it also points out an important reality: using these advanced open-source models isn't without its challenges.
In my experience, the accuracy gap between open-source and proprietary is negligible now and open-source is cheaper, faster, more customizable & sustainable for companies! No excuse anymore not to become an AI builder based on open-source AI (vs outsourcing to APIs)!
To set the stage, let's first revisit why deploying open-source LLMs is worthwhile in the first place. The growing proficiency of these models offers undeniable advantages, primarily data privacy and customization.
Why Deploying Open-Source LLMs
Data Privacy: Using open-source models means that customer data doesn’t have to be shared with third-party services. This self-hosted approach ensures heightened security and compliance with stringent data protection regulations.
Fine-tuning: Open source models allow for fine-tuning to cater to specific use cases. This customization isn’t typically possible with closed-source models, which often only allow for the usage of pre-trained weights without modifications.
Now that the 'why' behind deploying open-source LLMs is clear, let’s delve into the 'how'. Here's what Digits learned from deploying LLMs, summarized into actionable insights.
Key Lessons from Digits' Deployment Journey
1. Model Selection: Optimize for One, Not Many
In the world of machine learning, it's easy to get swept up in the hype of the latest models. Focus and specialization pay off better in the long run. We found it crucial to select a single model that aligns well with our needs and optimize our infrastructure around it. This focused approach allows for deeper integration and better performance.
2. Tooling and Infrastructure
When we initially embarked on this journey, we assumed that existing hyperscaler Machine Learning platforms would seamlessly support LLM deployments. We couldn’t have been more mistaken. We encountered various issues that significantly hampered our deployment efforts.
Choosing the Right Deployment Tooling: We eventually settled on Titan ML for our deployment needs, finding it to be an excellent combination between deployment flexibility and support by Titan ML.
3. Inference Optimizations
Making LLMs work in a production environment required us to address performance bottlenecks proactively. Here are the techniques that made a substantial difference:
Parallelization: Utilizing multiple GPUs can dramatically speed up inference times but it comes at a cost. Our expenses increased between 2-5x. Therefore, it's essential to evaluate if this trade-off works for your specific use case.
Efficient Attention (KV-Caching): Key-Value Caching can substantially improve inference speeds by storing previous results and reusing them. However, it’s vital to manage the memory usage intricately to avoid any performance degradation.
Quantization: This technique reduces the size and computational requirements of models by decreasing the precision of the numerical weights. We saw up to 90% reduction in inference costs, but it's highly problem-dependent. In some scenarios, the accuracy trade-offs might not be worth the cost savings.
Continuous Batching: This method involves grouping multiple inference requests together, thereby reducing the total number of computational steps. We saw a 2x speedup in inference time and hope for even higher speedups as this technology matures.
Putting It All Together: Our Use Cases
Digits employs Open Source LLMs for various applications, including understanding documents and converting unstructured data into structured data. Each use case brings its own set of challenges and optimization opportunities.
For instance, in document understanding, the quality of the input tokens and the pre-processing steps dramatically affect the accuracy and performance of the model.
Infrastructure Lessons
While the nuances of model selection and inference optimization are critical, don't overlook the mundane aspects of infrastructure, which can make or break the success of your deployment. Make sure you have the right backend systems in place that are resilient and scalable. Equally crucial is to employ monitoring and alerting systems that allow for rapid identification and resolution of any issues.
Conclusion and Next Steps
Deploying Large Language Models in production environments isn’t straightforward yet, but it is becoming increasingly simpler just 18 months ago. Our experience has shown that with the right model, tools, and optimizations, it is possible to deploy these models efficiently.
For those interested in diving deeper into our strategies and lessons learned, we’ve made our full presentation slides available below. They provide a more detailed breakdown of each technique and offer further insights into our deployment journey.
By sharing our experiences, we hope to contribute to the collective wisdom in the ML community, encouraging more organizations to harness the power of open-source LLMs safely and effectively. Happy deploying!
If you haven't already, check out our AI in Production 2024 Conference recap to learn more about the latest trends and insights from the event.
Tucked away in the scenic splendor of Asheville, North Carolina, the AI in Production conference was held on July 19, 2024, bringing together some of the brightest minds in machine learning and artificial intelligence. The intimate gathering of 85 participants included ML experts and AI enthusiasts from renowned tech giants like Tesla, Intuit, Ramp, GitHub, and Digits. The focus of this event was clear: to delve deep into the real-world, production-level applications of machine learning, with a keen interest in the burgeoning field of Large Language Models (LLMs).
Unlike many conferences plagued by buzzwords and marketing fluff, AI in Production distinguished itself by being refreshingly genuine. The sessions were dedicated to practical machine learning solutions, steering clear of hype-driven narratives. It was a platform where every presenter showcased solutions to their problems, fostering an environment of learning, problem-solving, and genuine curiosity.
Unearthing Practical Solutions
The conference's essence lay in its authenticity. Each presentation was rooted in real-world experiences, offering attendees valuable insights into the successes and challenges of deploying large language models in production environments. Here are three presentations that stood out to Digits’ ML team.
JAX vs. PyTorch: A Comparative Perspective by Tesla
Sujay S Kumar, a Tesla engineer, delivered one of the standout talks and embarked on a detailed comparison between JAX and PyTorch, two leading frameworks in the machine learning landscape. The session was rich with technical insights, shedding light on the nuances of each framework. The engineer discussed the strengths and weaknesses of JAX in terms of flexibility and performance optimization, juxtaposed with PyTorch’s robust ecosystem and user-friendly interface. This comparative analysis equipped the audience with the knowledge to make informed decisions depending on their specific project needs and infrastructural considerations.
Ethical Implementation: Insights from GitHub
The senior Engineering Director, Christina Entcheva from GitHub, led a thought-provoking session emphasizing the ethical dimensions of deploying large language models. As these models become increasingly pervasive, the ethical implications surrounding data privacy, algorithmic bias, and societal impact are paramount. Christina fostered a sense or urgency regarding model bias and ensuring AI systems' fairness, transparency, and accountability. This talk was a timely reminder of the importance of ethical considerations, resonating deeply with the audience and sparking meaningful discussions on integrating ethical practices into everyday AI operations.
Tackling Data Curation: Best Practices from Dendra Systems’ Senior Data Scientist
Another illuminating talk was given by Richard Decal, a Senior Data Scientist from Dendra Systems, who deep dived into the challenges of curating production data sets once a machine learning model is deployed. The talk focused on the data drift phenomenon—where the target variable's statistical properties change over time, rendering the model less accurate. The data scientist shared valuable strategies for monitoring and mitigating data drift, emphasizing the importance of continuous evaluation and adjustment of data pipelines to maintain model performance. This session was particularly beneficial for practitioners seeking to enhance the robustness and reliability of their deployed models.
Beyond the Sessions: Meaningful Interactions
One of the conference's highlights was the vibrant conversations during and after the sessions. The atmosphere was charged with intellectual curiosity as participants explored the latest trends in machine learning. The intimate setting facilitated meaningful networking opportunities, allowing attendees to connect more personally.
The conference's practical focus enabled attendees to go beyond theoretical knowledge and engage with tangible solutions. Every participant left the conference with actionable takeaways, ready to implement the insights gained into their projects.
A Glimpse into the Future: Anticipation for Next Year
The resounding success of the AI in Production conference has left participants eagerly anticipating the next edition. Witnessing the cutting-edge advancements in large language models and their practical applications was a rare opportunity. The conference's genuine, no-nonsense approach ensured that every moment spent was valuable, fostering a culture of learning, innovation, and ethical AI deployment.
A Heartfelt Thank You
A significant part of the conference’s success can be attributed to the meticulous planning and execution by Julio Baros and the dedicated team of volunteers. Their efforts in organizing and facilitating the event were commendable, ensuring a seamless experience for all attendees. The invitation extended to Digit’s ML team was greatly appreciated, and the team was honored to be part of such a prestigious gathering.
Conclusion
The AI in Production conference in Asheville, NC, on July 19, 2024, was more than just an event; it was a confluence of brilliant minds, innovative solutions, and forward-thinking discussions. Focusing on practical, production-level applications of large language models provided attendees with a treasure trove of knowledge and insights. The captivating presentations, engaging conversations, and the stunning backdrop of Asheville made it an unforgettable experience.
We at Digits are already looking forward to returning next year, eager to continue the journey of learning and discovery in the ever-evolving landscape of machine learning and artificial intelligence.
In the meantime, let’s carry forward the lessons learned, implement the best practices shared, and strive for excellence in deploying large language models. A big thank you once again to Julio Baros and all the conference volunteers for making this event a remarkable success. Here’s to pushing the boundaries of AI and machine learning, one practical solution at a time.
Interested in learning more about Digits' presentation at the AI in Production conference? Check out our full presentation slides for an in-depth look at our journey with large language models.
Digits at Google I/O'24: A Fusion of Innovation and Collaboration
The Google I/O and the Google Developer Conference held in Mountain View, California, have always been a beacon of new technology and innovation, and 2024 was no exception. Like last year, Digits had the privilege of being invited to participate in this global gathering of ML/AI experts. Our team of engineers was thrilled and honored to be a part of such a dynamic and forward-thinking event.
Engaging with the Developers Advisory Board
One of the key highlights for us was participating in Google’s Developer Advisory Board meeting. This not only provided us with a platform to share our insights but also allowed us to exchange ideas with Google's Developer X group and learn about upcoming products.
A Closer Look at Google’s Innovations
From Digits' perspective, several announcements and tools stood out, each promising to significantly impact our journey with machine learning and artificial intelligence. Here’s a rundown of the highlights:
Gemma 2: A Leap Forward for Open Source LLMs
Google unveiled Gemma 2, a new model designed to enhance the capabilities of open-source large language models (LLMs). What makes Gemma 2 truly remarkable is its optimization for specific instance types, which will help reduce costs and improve hardware utilization. This is a significant advancement, as it enables more efficient and cost-effective deployment of ML models, a crucial factor for any tech-driven company.
Responsible Generative AI Toolkit
Another noteworthy introduction was Google's Responsible Generative AI Toolkit. This comprehensive toolkit provides resources to apply best practices for responsible use of open models like the Gemma series. It includes:
Guidance on Setting Safety Policies: Frameworks and guidelines for establishing robust safety policies when deploying AI models.
Safety Tuning and Classifiers: Tools for fine-tuning safety mechanisms to ensure that AI behaves as intended.
Model Evaluation: Metrics and methodologies for thorough evaluation of model safety.
Learning Interpretability Tool (LIT): This tool enables developers to investigate the behavior of models like Gemma and address potential issues. It offers a deeper understanding of how models make decisions, which is crucial for transparency and trustworthiness.
Methodology for Building Robust Safety Classifiers: Techniques to develop effective safety classifiers even with minimal examples, ensuring that AI systems can operate reliably in diverse scenarios.
LLM Comparator: A Visualization Tool for Model Comparison
The LLM Comparator is another brilliant tool that grabbed our attention. It is an interactive visualization instrument designed to analyze LLM evaluation results side-by-side. This tool facilitates qualitative analysis of how responses from two models differ, both at example- and slice-levels. For engineers and developers, this means more insightful comparisons and a stronger ability to refine and improve their models.
Reflecting on Our Experience
Being invited to Google I/O once again, especially being part of the Developer Advisory Board meeting for the second consecutive year, is a testament to the growing partnership and mutual respect between Digits and Google. We are thankful for this opportunity and excited about the collaborations and advancements that will emerge from these engagements.
Our time at Google I/O’24 was not only inspiring but also a powerful reminder of the incredible pace at which technology evolves. With tools like Gemma 2, the Responsible Generative AI Toolkit, and the LLM Comparator, we are on the brink of a new era in AI and ML development. At Digits, we look forward to integrating these innovations into our work and harnessing their potential to create transformative solutions.
Big thanks goes out to the Jeanine Banks and the entire Google team for hosting us at the Google Developer Advisory Board meeting.
In April, Digits' expert machine-learning team was invited to conduct a lecture at the University of Washington. The event occurred at the Foster School of Business and was attended by a mixed crowd of students and faculty alike.
75 students flocked to the lecture, demonstrating the growing interest in these ground-breaking technologies, such as machine learning, that are paving future paths in finance. Undeniably, the turnout indicated the growing curiosity about practical applications of machine learning in the world of finance.
The lecture provided an overview of machine learning and Generative AI (GenAI) and explored their impacts in the finance sector. Attendees delved deep into understanding GenAI's specific use cases in finance, with our team sharing their exhaustive research findings and experienced insights to provide a wider perspective of GenAI's potential role in revolutionizing traditional accounting methods.
The University of Washington's proactive approach in inviting the Digits team and the hearty attendance underlines the increasing investment and gravitation towards AI technologies in finance. This trend is expected to continue as technology continues to weave its way into the world of finance.
In case you missed it, you can access the lecture slides below to help better understand this technological revolution.